Кластеризация клиентской базы компании
Задача кластеризации клиентской базы является одним из ключевых шагов для успешного решения задачи управления группами клиентов.
В общем смысле кластеризация клиентской базы - это разделение потребителей по группам в соответствии с устойчивыми признаками, называемыми "признаками сегментирования"[33].
Выбор признаков сегментирования зависит от целей кластеризации. Как правило, в качестве признаков сегментирования используются:• географические характеристики (региональное деление);
• психографические характеристики (типы личности, темперамент, социальная среда);
• характеристики потребительского поведения (интенсивность потребления, категории покупаемых товаров и сумма покупки);
• демографические признаки (пол, возраст, семейное положение, образование).
Для повышения эффективности проводимых маркетинговых мероприятий при сегментации клиентской базы, как правило, используют характеристики покупательского поведения: частоту покупок и величину среднего чека. Иногда в качестве дополнительных параметров учитывают общее время взаимодействия клиента и компании, и период времени, прошедший с последней покупки клиента (давность покупки).
В результате сегментации с использованием указанных выше параметров выделяют следующие группы клиентов:
• случайные покупатели («делали хотя бы одну покупку, средний чек - минимальный по клиентской базе»);
• покупатели (совершали несколько покупок в течение определенного периода времени);
• постоянные клиенты («периодически покупают»);
• приверженцы («очень активные клиенты, величина среднего чека выше среднего уровня, участвуют в большинстве маркетинговых мероприятий компании);
• отказники (они же могут быть потенциальными или бесперспективными).
Каждая группа, в свою очередь, может быть разбита на несколько подгрупп в зависимости от социально-демографических показателей (пол, возраст, образование и т.д.).
Полученные сегменты клиентов можно представить в виде клиентского куба (рис.6).

Рисунок 6. Клиентский куб компании.
Отдельного внимания при сегментации клиентской базы занимает проблема определения группы "отказников". Основной проблемой при выделении данной группы клиентов является определение момента ухода клиента из компании. Данная проблема рассматривается, в частности, в работах Фадера и Харди [61, 96].
Так, Фадер и Харди выделяют два типа взаимоотношений с клиентами - контрактные и неконтрактные.
Контрактные взаимоотношения характеризуются тем, что момент прерывания клиентом взаимоотношений с компанией может быть однозначно определен.
Неконтрактные взаимоотношения характеризуются тем, что момент времени, в который клиент прекращает свои взаимодействия с компанией, не контролируется организацией. Данные отношения характерны для компаний, работающих в секторе FMCG. Так, в торговых фирмах клиент не предупреждает компанию о том, что он больше не будет совершать покупки в ее магазинах. Таким образом, компания не может с достоверностью сказать, что в случае, если клиент сделал покупку n месяцев назад, то он больше не вернется в компанию.
В рамках данного исследования в качестве периода времени, после которого считается, что клиент разорвал свои взаимоотношения с компанией, выбирается максимальный интервал времени между последовательными покупками, в течение которого 95% клиентов, попавших в выборку, неоднократно совершали покупки.
Для определения этого временного интервала для каждого клиента рассчитываются интервалы между покупками и выбирается максимальный из них:
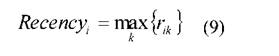
где Recencyi- максимальный интервал между покупками клиента (в месяцах);
rik- величина k-го интервала между последовательными покупками і-го клиента (в месяцах);
к - количество рассматриваемых интервалов, равное количеству месяцев (N),в которых клиентом были совершены покупки, за вычетом единицы (N - 1).
Далее на основе частотной таблицы распределения клиентов в зависимости от величины максимального интервала между покупками
определяется граница значения максимального интервала между покупками, в рамках которой 95% клиентов совершали повторную покупку.
В качестве инструментария сегментации используются методы кластерного анализа [32]. Кластерный анализ предназначен для разбиения совокупности объектов на однородные группы (кластеры или классы) таким образом, чтобы элементы, входящие в одну группу были максимально "схожи" (по какому-то заранее определенному критерию), а элементы из разных групп были максимально "отличными" друг от друга. При этом число групп может быть заранее неизвестно, также может не быть никакой информации о внутренней структуре этих групп. Наиболее известные и часто используемые методы кластерного анализа - иерархический кластерный анализ и кластеризация методом k-средних.
Цель иерархических методов кластерного анализа заключается в объединении (или разделении, в зависимости от конкретного метода) объектов в достаточно большие кластеры, используя некоторую меру сходства или расстояние между объектами. Множество методов иерархического кластерного анализа различается не только используемыми мерами сходства и различия, (например, евклидово расстояние или метрика городских кварталов), но и алгоритмами классификации (например, методы ближайшего или дальнего соседа, метод межгруппового связывания, метод Варда). Типичным результатом такой кластеризации является иерархическое дерево.
Наиболее известным иерархическим методом кластеризации является метод ближайшего соседа. Перед началом работы алгоритма рассчитывается матрица расстояний между объектами. На каждом шаге в матрице расстояний ищется минимальное значение, соответствующее расстоянию между двумя наиболее близкими кластерами. Найденные кластеры объединяются, образуя новый кластер. Эта процедура повторяется до тех пор, пока не будут объединены все кластеры. При
использовании метода ближайшего соседа особое внимание следует уделять выбору меры расстояния между объектами. На основе нее формируется начальная матрица расстояний, которая и определяет весь дальнейший процесс классификации. Выбор результирующего числа полученных кластеров осуществляется исследователем.
Метод кластеризации k-средних требует изначального задания числа кластеров, на которые должно быть поделено исследуемое множество наблюдений. Алгоритм кластеризации представляет собой последовательное перераспределение элементов кластеров между собой так, чтобы получить максимально удаленные друг от друга кластеры. В случае если дальнейшее перераспределение элементов не приводит к улучшению функции цели кластеризации, то процесс останавливается.
В рамках данного исследования используется метод кластеризации k-средних.
2.2.